大模型分布式训练
Contents
大模型分布式训练#
为什么我们需要机器学习的分布式训练?#
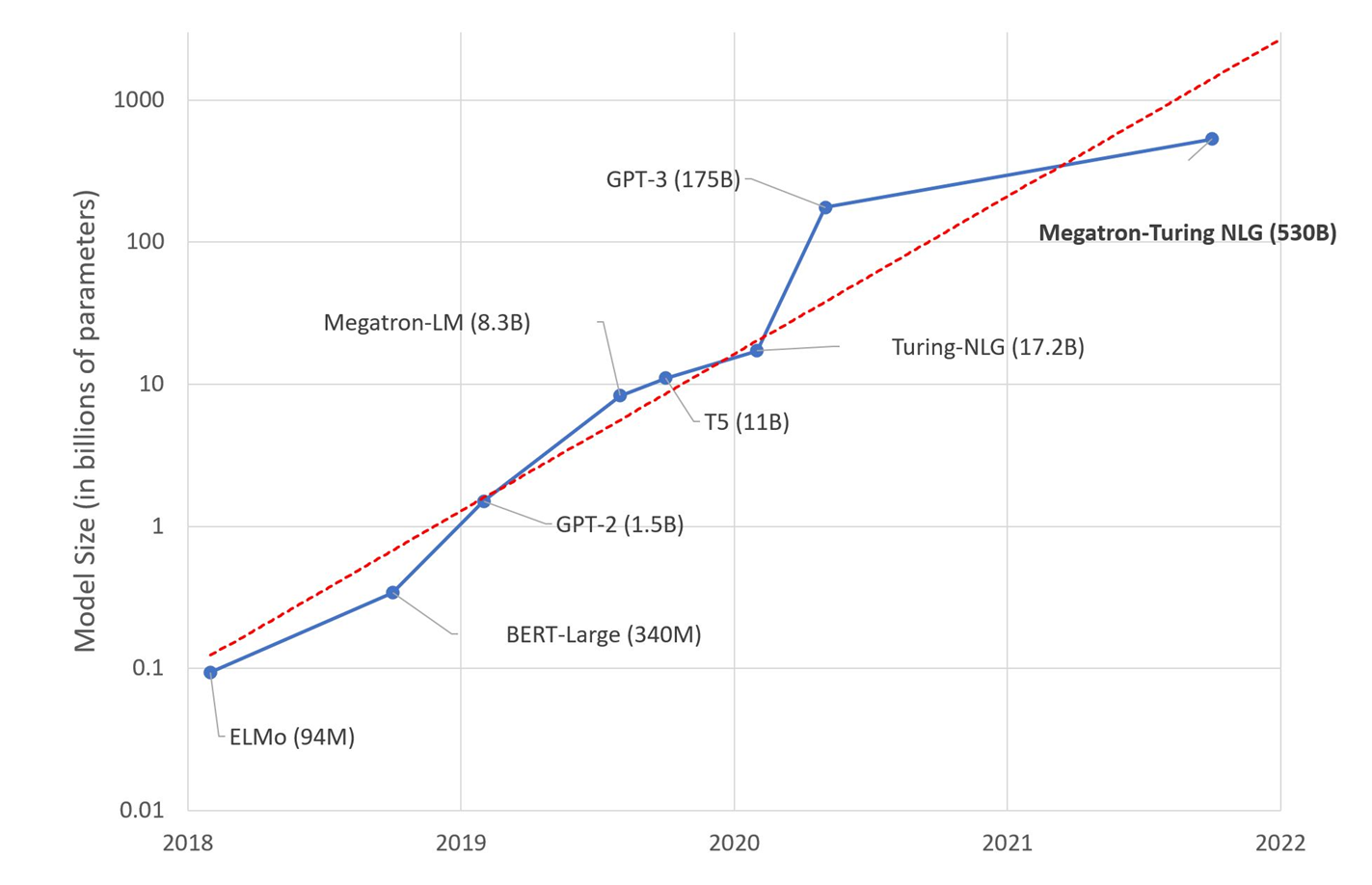
模型规模迅速增加。2015年的 ResNet50 有2000万的参数, 2018年的 BERT-Large有3.45亿的参数,2018年的 GPT-2 有15亿的参数,而2020年的 GPT-3 有1750亿个参数。很明显,模型规模随着时间的推移呈指数级增长。目前最大的模型已经超过了1000多亿个参数。而与较小的模型相比,超大型模型通常能提供更优越的性能。图片来源: HuggingFace
内存效率: 训练万亿参数模型的内存要求远远超出了单个 GPU 设备中可用的内存要求。以混合精度使用 Adam 优化器进行训练需要大约 16 TB 的内存来存储模型状态(参数、梯度和优化器状态)。相比之下,最先进的NVIDIA A100 GPU只有40千兆字节(GB)的内存。它需要 400 个这样的 GPU 的集体内存来存储模型状态。 激活会消耗额外的内存,这些内存会随着批大小的增加而增加。仅使用单位批大小训练的万亿参数模型会产生超过 1 TB 的激活内存。激活检查点通过换取额外的计算将此内存减少到大约 20 GB,但内存要求对于训练来说仍然大得令人望而却步。 模型状态和激活必须在可用的多个 GPU 设备之间有效分区,以使此类模型甚至可以在不耗尽内存的情况下开始训练。
数据集规模迅速增加。对于大多数机器学习开发者来说,MNIST 和 CIFAR10 数据集往往是他们训练模型的前几个数据集。然而,与著名的 ImageNet 数据集相比,这些数据集非常小。谷歌甚至有自己的(未公布的)JFT-300M 数据集,它有大约3亿张图片,这比 ImageNet-1k 数据集大了近300倍。
计算能力越来越强。随着半导体行业的进步,显卡变得越来越强大。由于核的数量增多,GPU是深度学习最常见的算力资源。从2012年的 K10 GPU 到2020年的 A100 GPU,计算能力已经增加了几百倍。这使我们能够更快地执行计算密集型任务,而深度学习正是这样一项任务。
计算效率: 端到端训练一个万亿参数模型需要大约 5,000 个 zettaflops(即 5 个,后面有 24 个零;基于 OpenAI 的扩展工作定律)。训练这样一个模型需要 4,000 个 NVIDIA A100 GPUS,以 50% 的计算效率运行大约 100 天。 虽然大型超级计算 GPU 集群可以拥有超过 4,000 个 GPU,但由于批量大小限制,在这种规模下实现高计算效率具有挑战性。计算效率随着通信时间的增加而提高。此比率与批量大小成正比。但是,可以训练模型的批量大小有一个上限,超过上限,收敛效率会迅速下降。 世界上最大的模型之一 GPT-3 使用大约 1,500 的批量大小进行训练。对于 4,000 个 GPU,即使是 4,000 个的自由批处理大小也只允许每个 GPU 的批处理大小为 1,并限制了可扩展性。
如今,我们接触到的模型可能太大,以致于无法装入一个GPU,而数据集也可能大到足以在一个GPU上训练一百天。这时,只有用不同的并行化技术在多个GPU上训练我们的模型,我们才能完成并加快模型训练,以追求在合理的时间内获得想要的结果。
分布式计算#
Amdahl’s law
Gustafson’s law
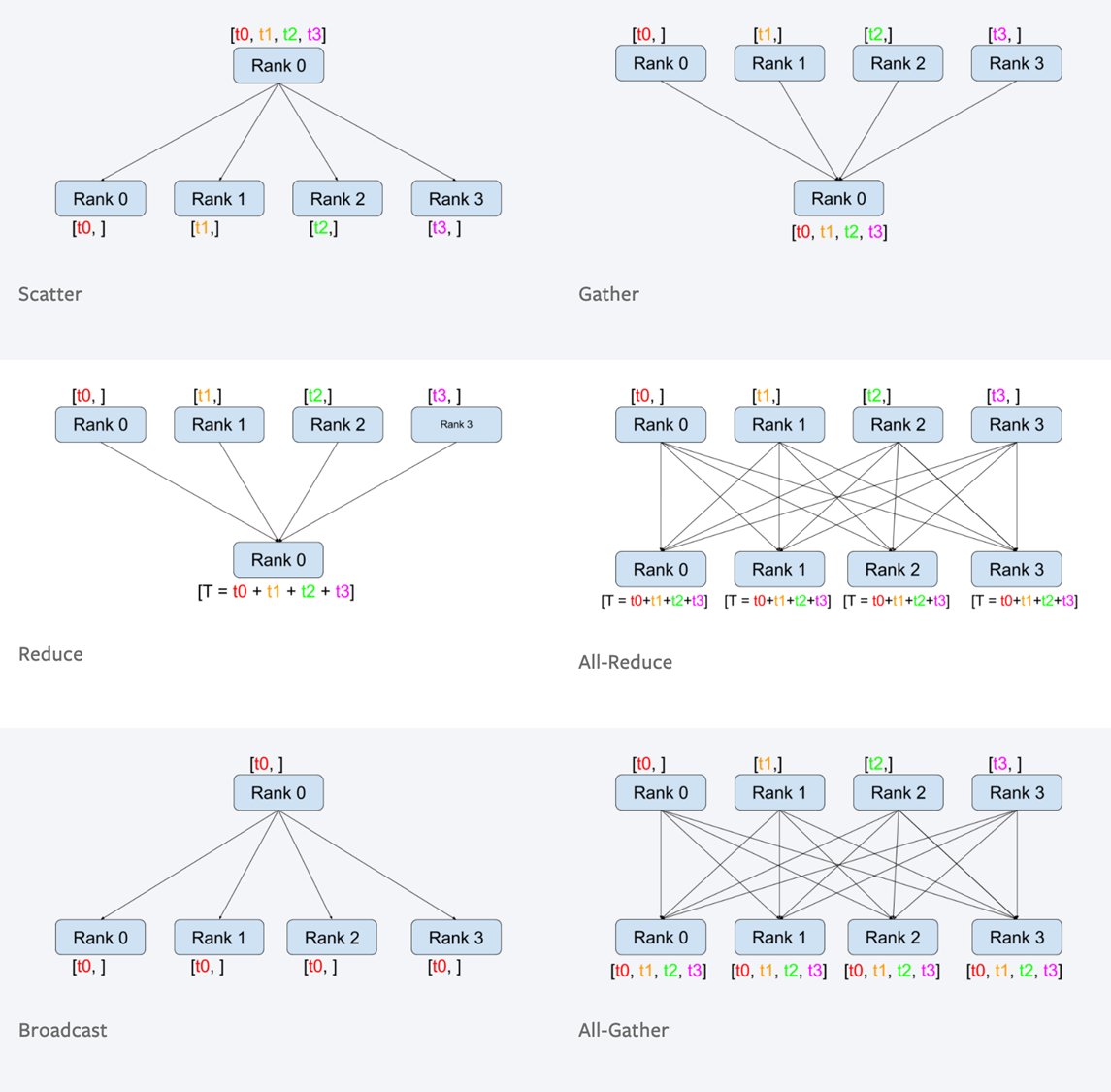
通讯原语#
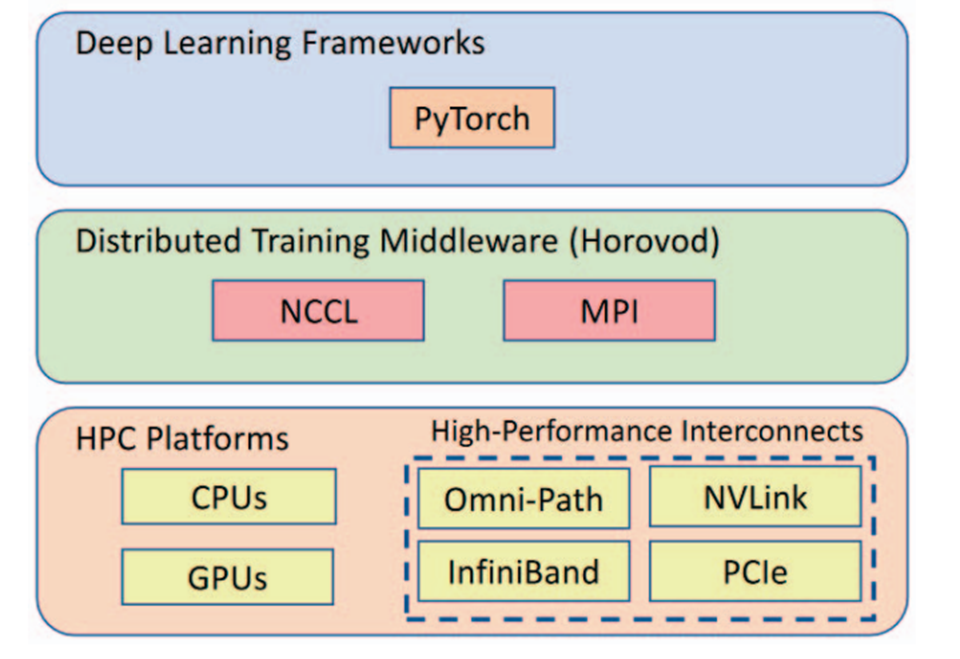
分布式深度学习#
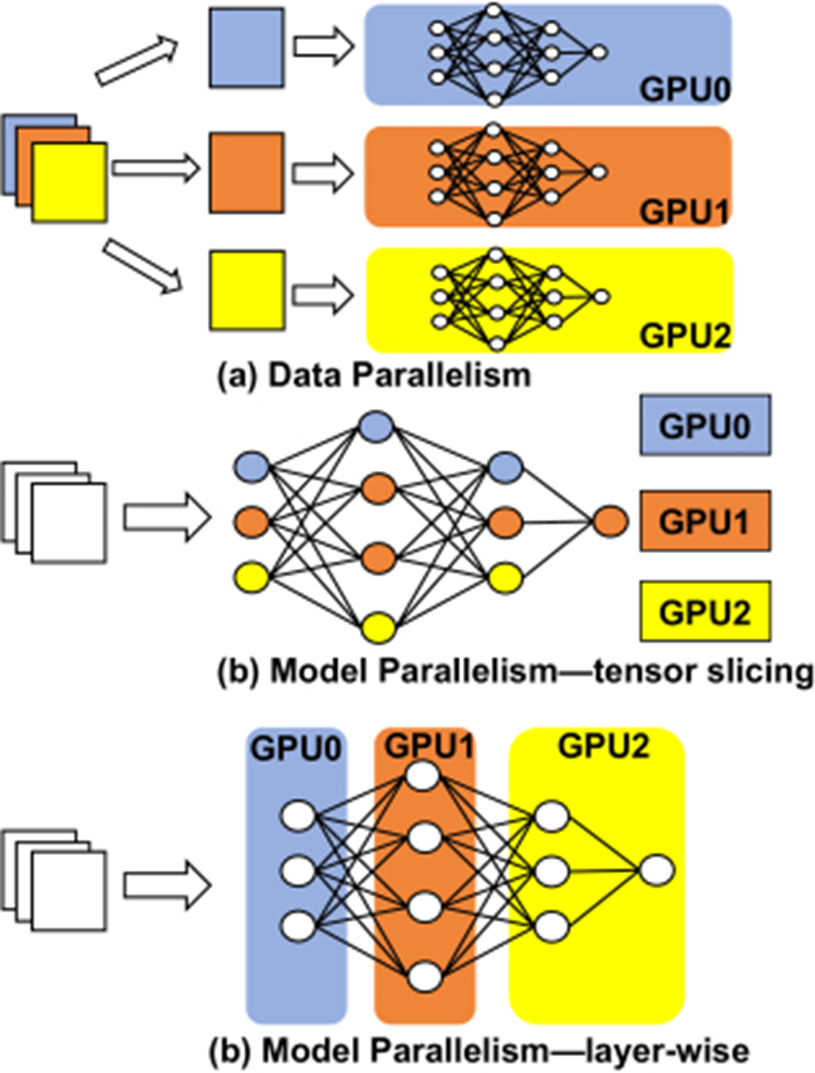
数据并行
张量并行
流水线并行
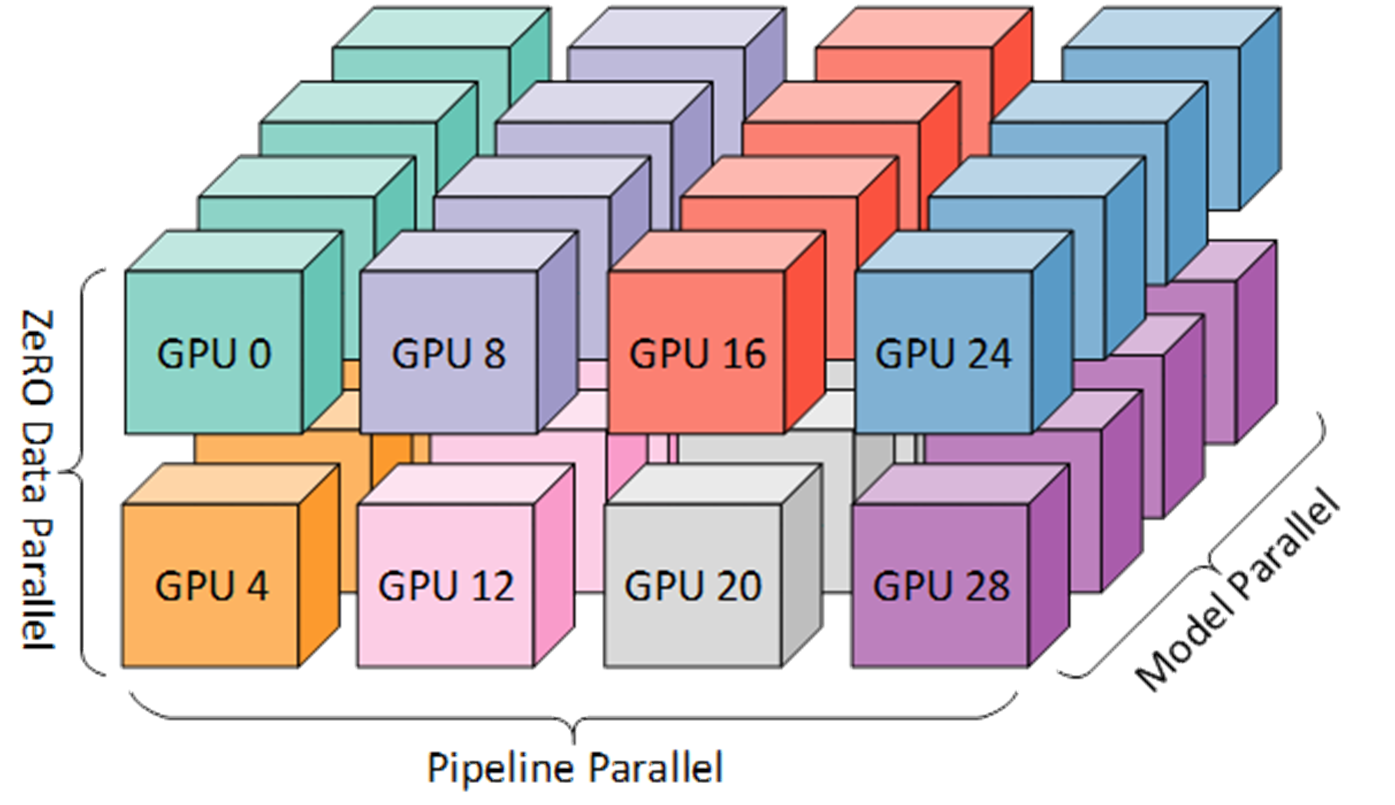
混合并行
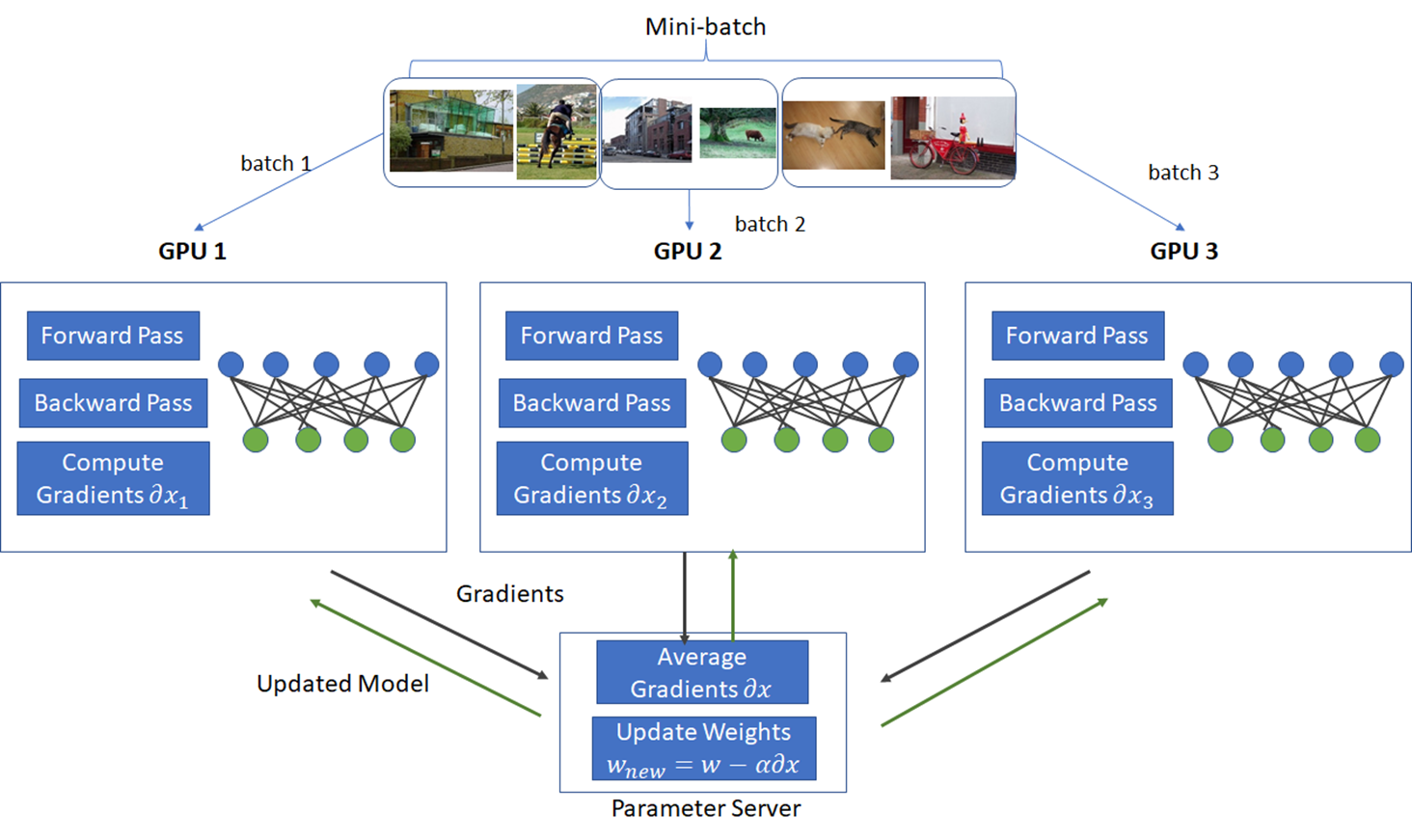
数据并行#
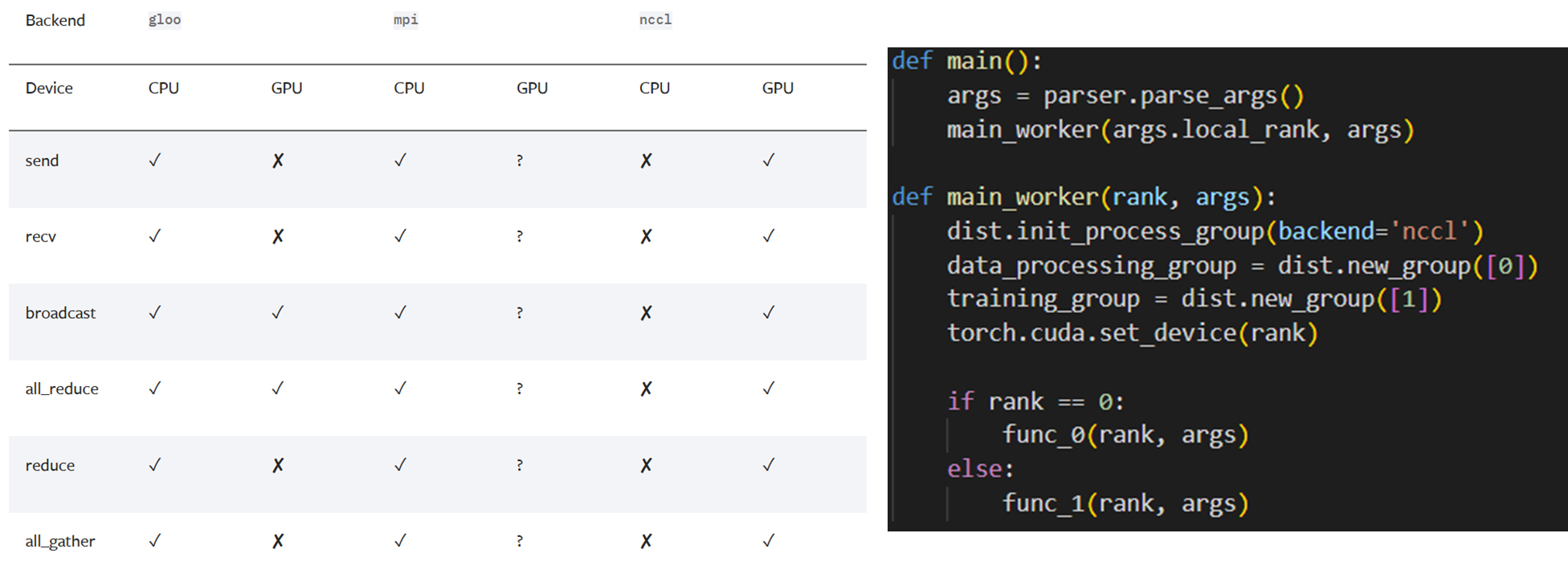
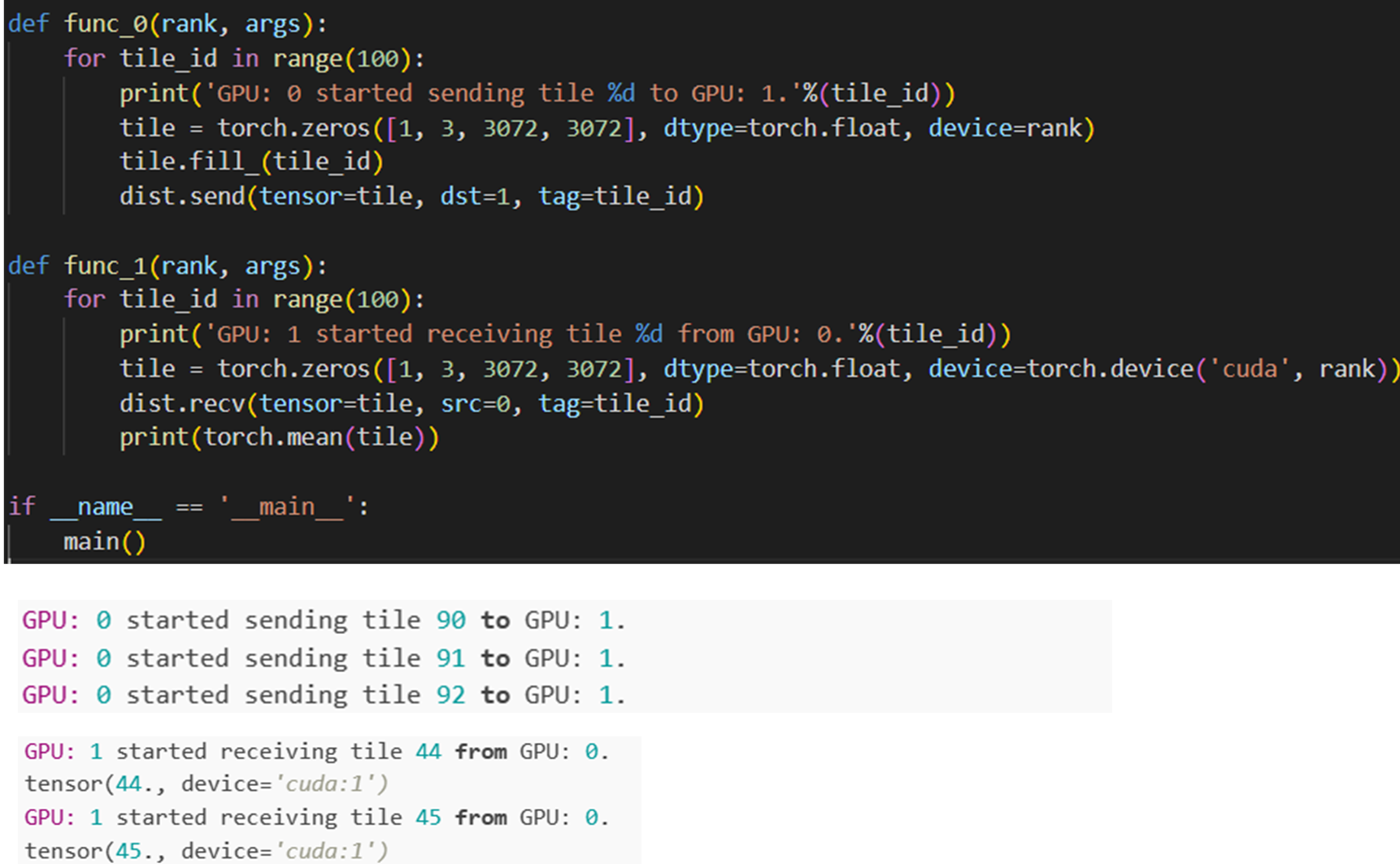
torch.distributed#
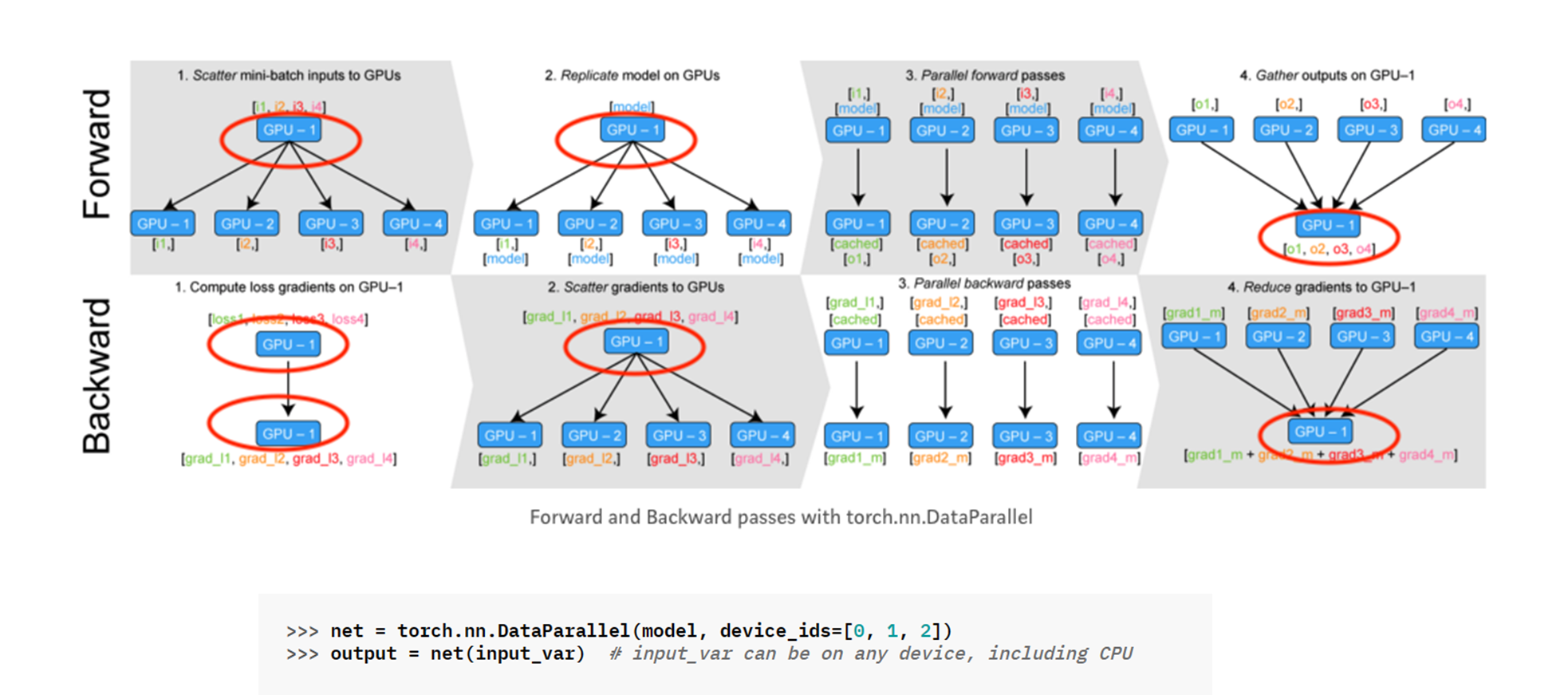
torch.nn.DataParallel#
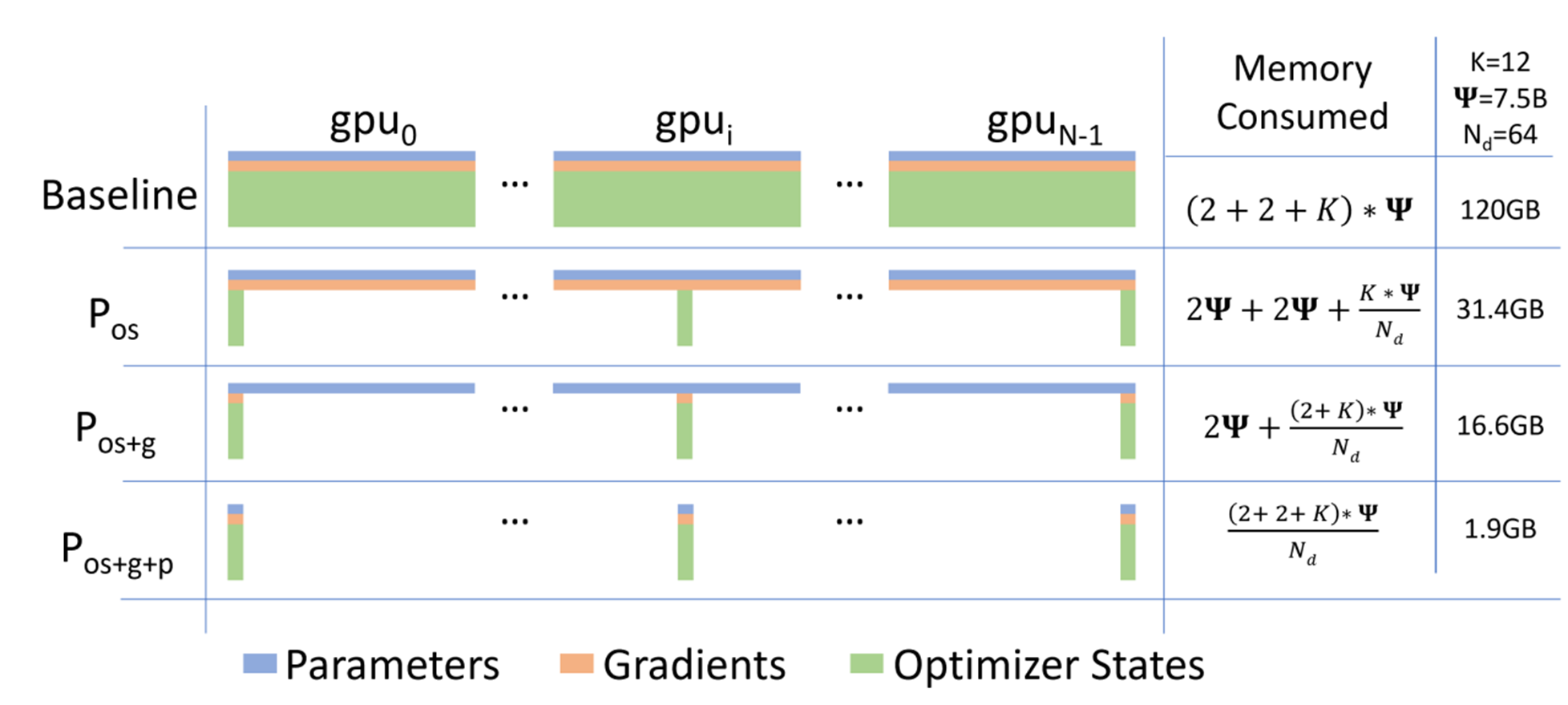
Zero Redundancy Optimizer#
model states:
optimizer states (such as momentum and variances in Adam
Gradients
parameters.
remaining memory:
activation
temporary buffers
unusable fragmented memory
Zero是由一系列论文[RRRH20],[RRA+21],[RRR+21]构成的工作。
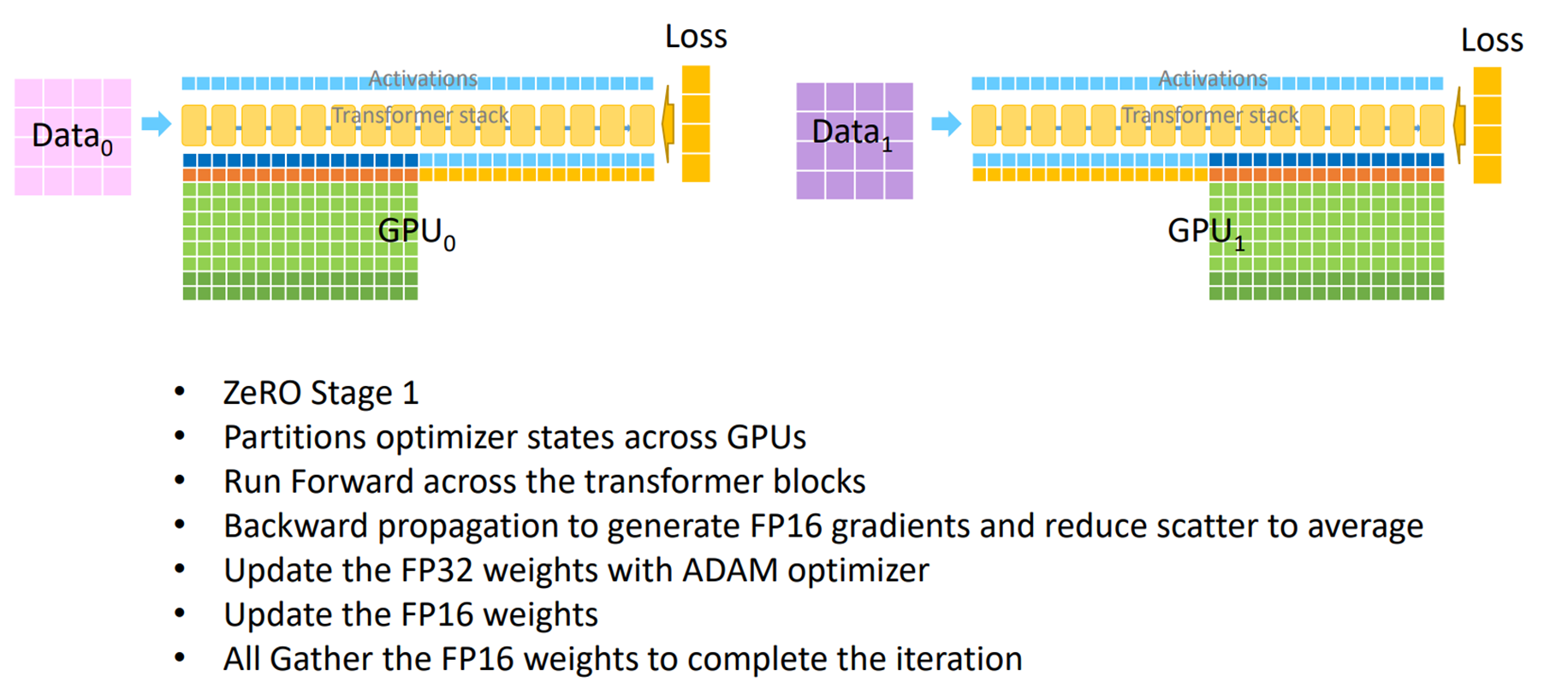
ZeRO-DP Stage1 : Optimizer State Partitioning#
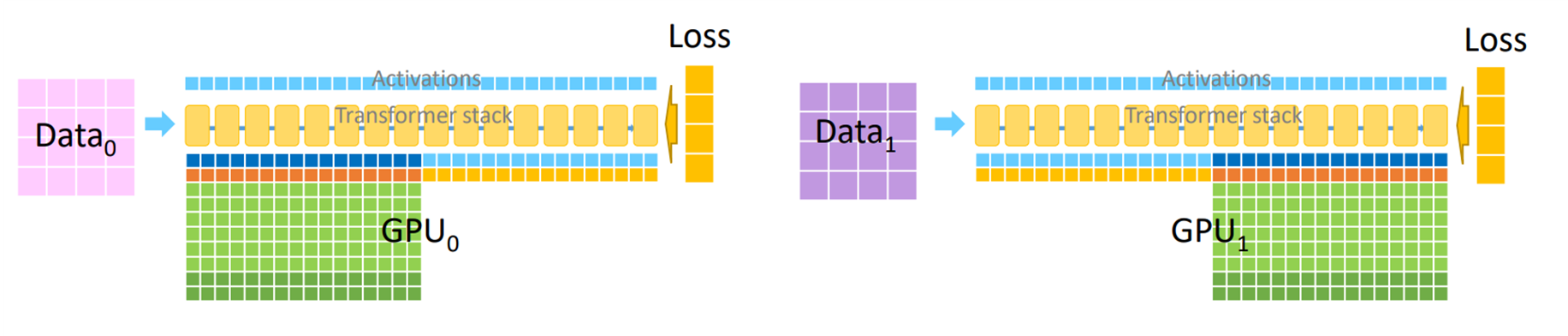
ZeRO-DP Stage2 : Gradient Partitioning#
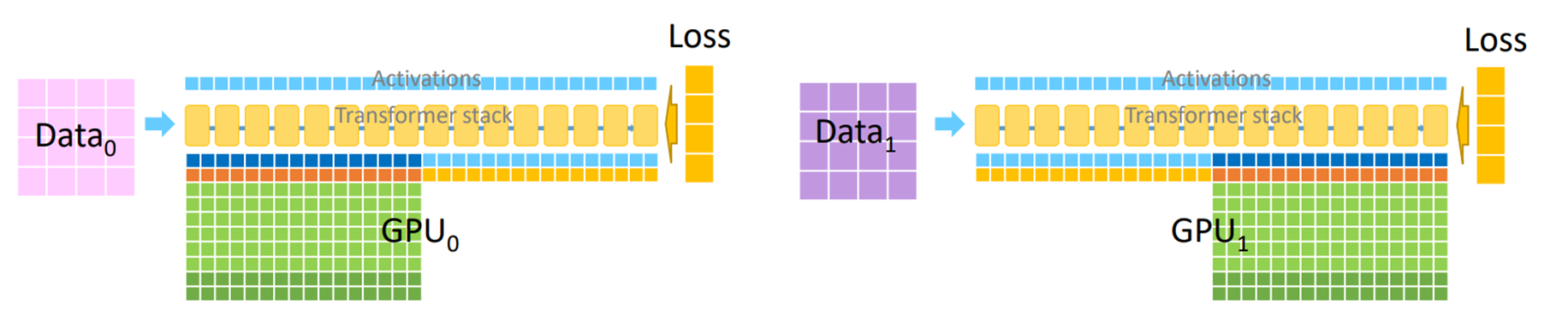
ZeRO-DP Stage3 : Parameter Partitioning#
ZeRO-R#
Partitioned Activation Checkpointing
Constant Size Buffers
Memory Defragmentation
Communication Analysis of ZeRO-DP#

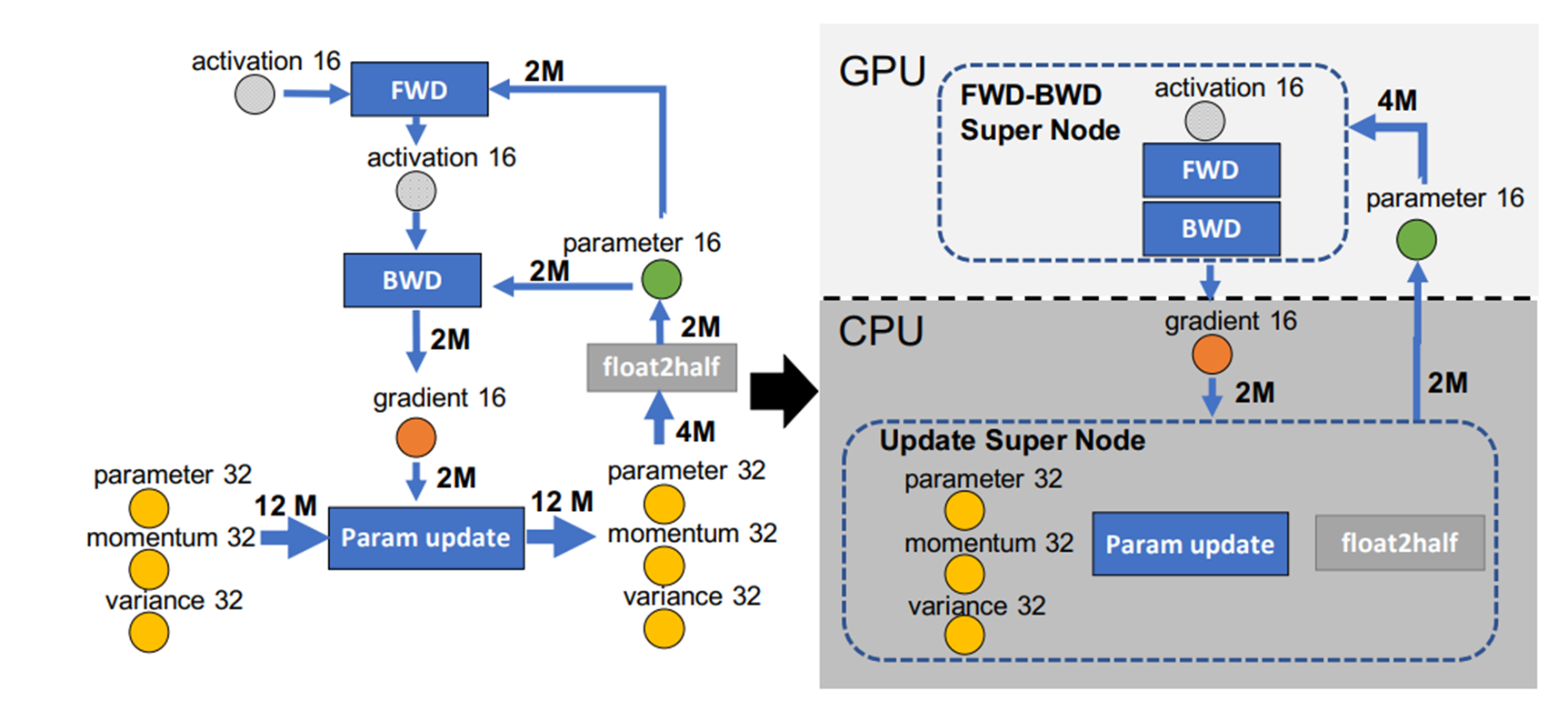
ZeRO-Offload#
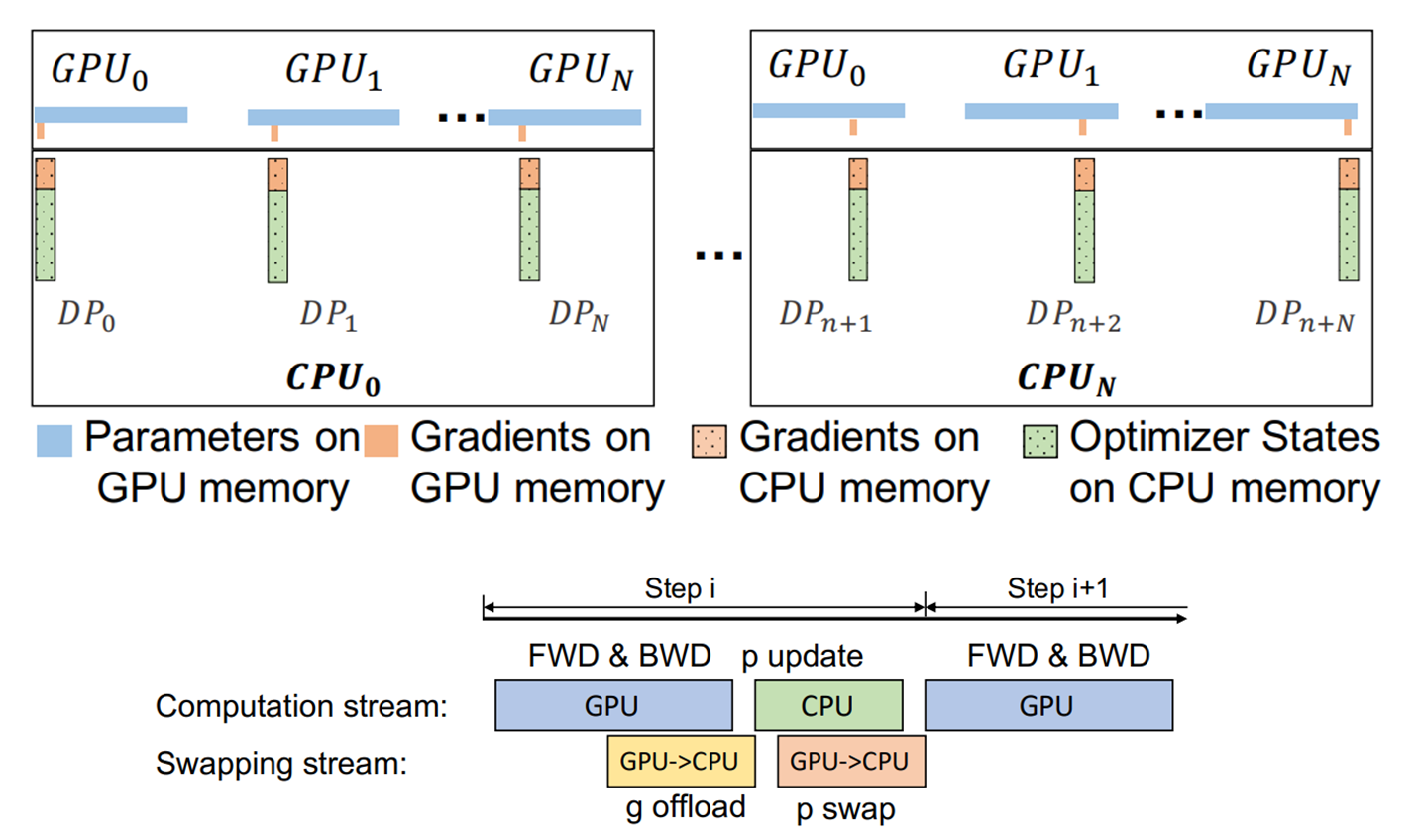
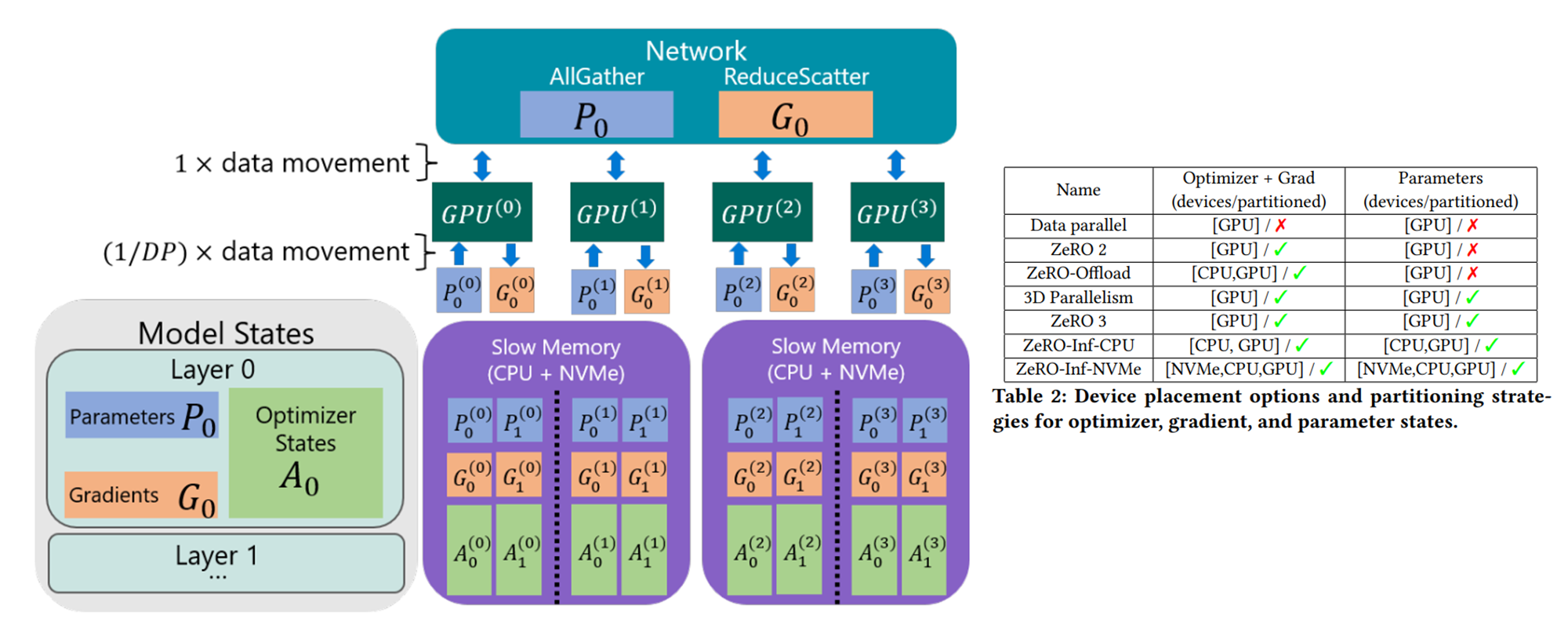
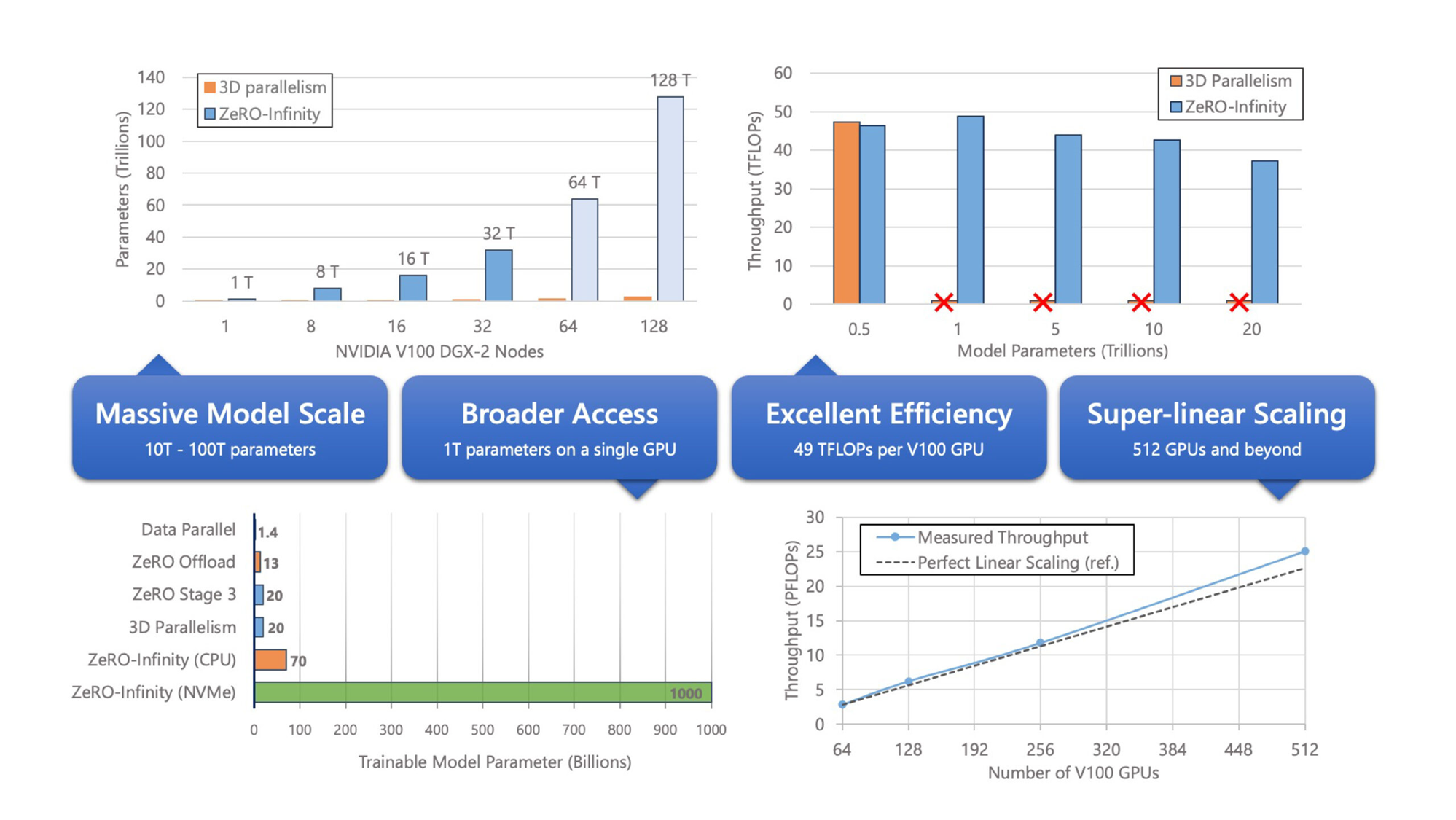
ZeRO-Infinity#
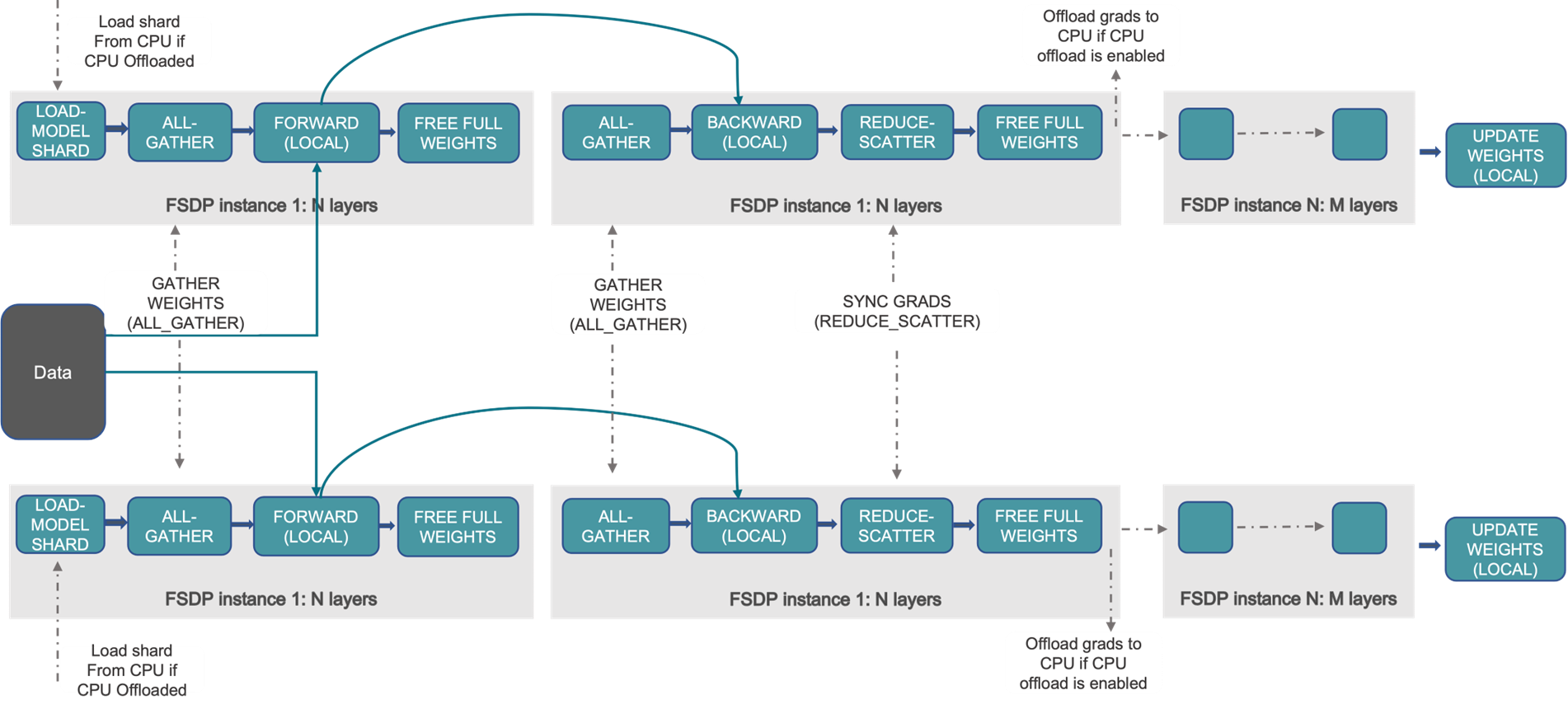
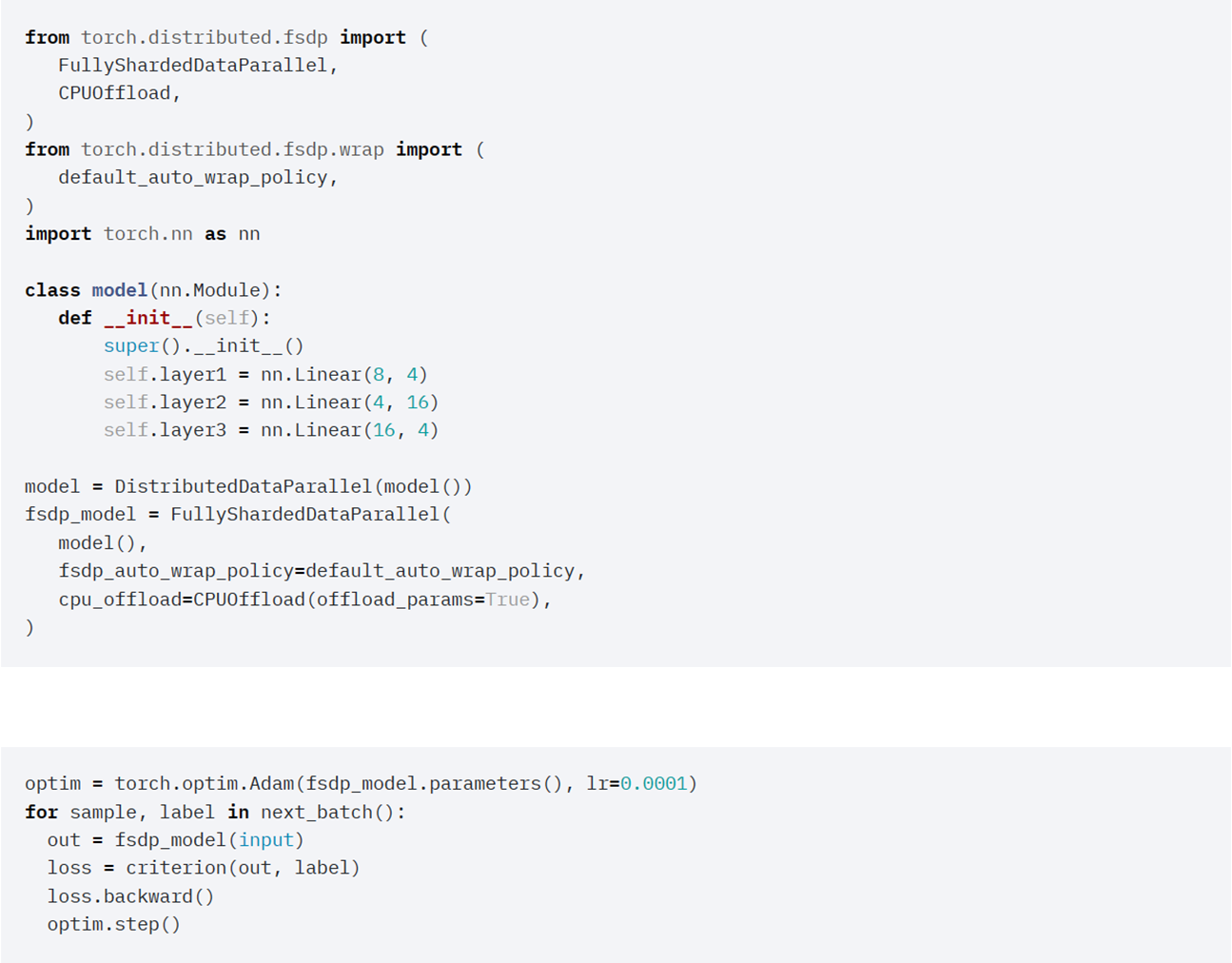
PyTorch: FullyShardedDataParallel#
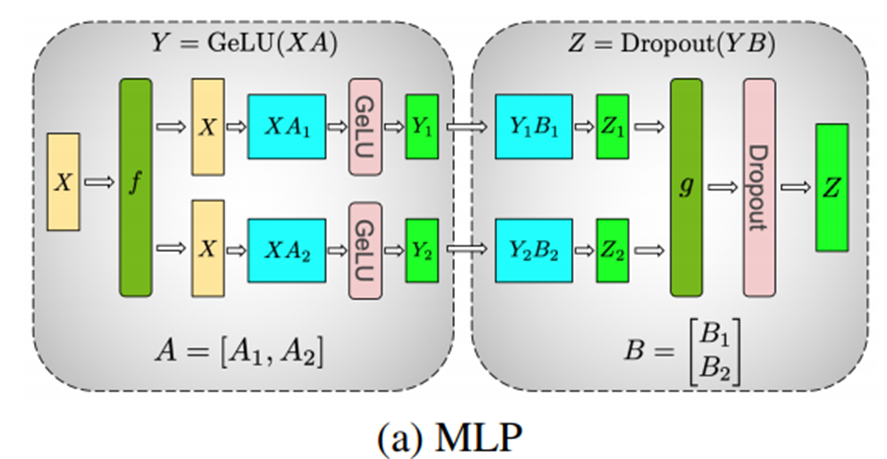
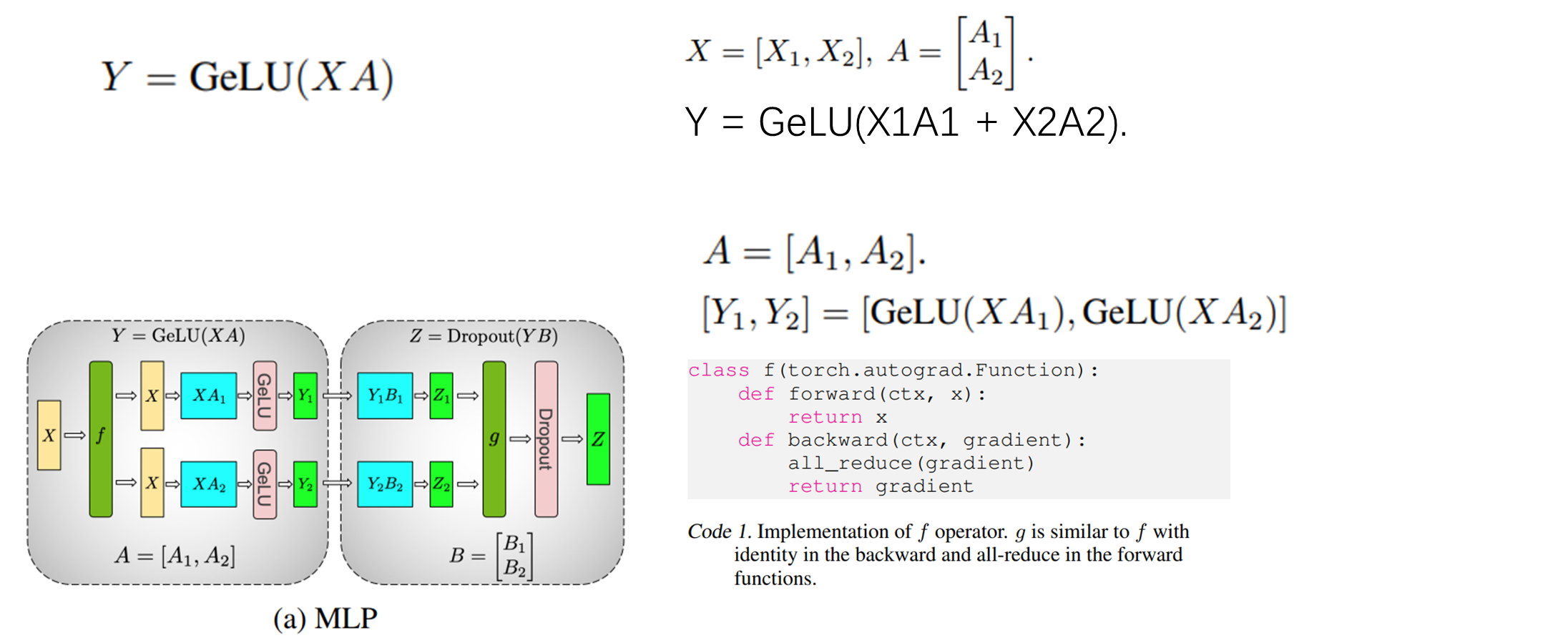
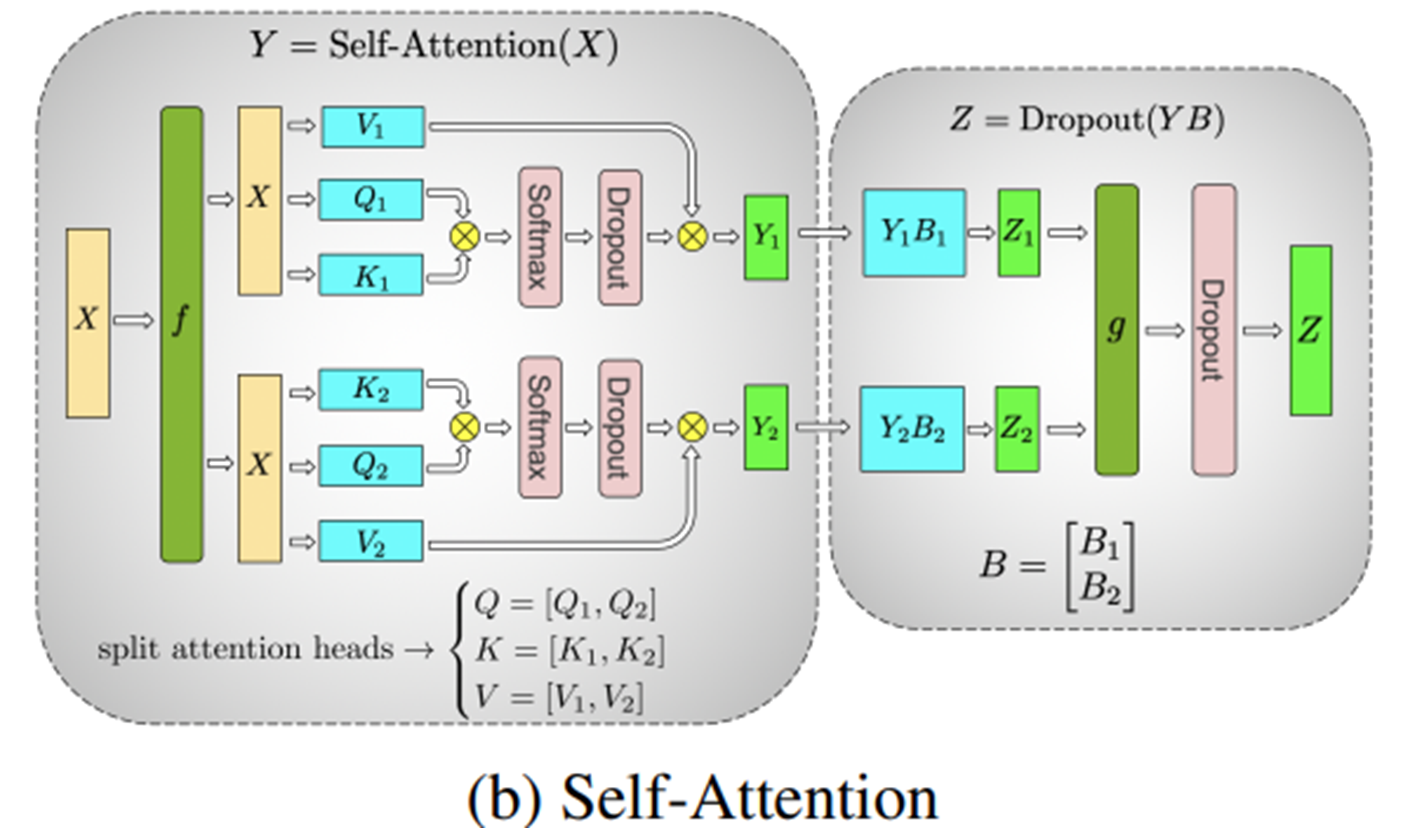
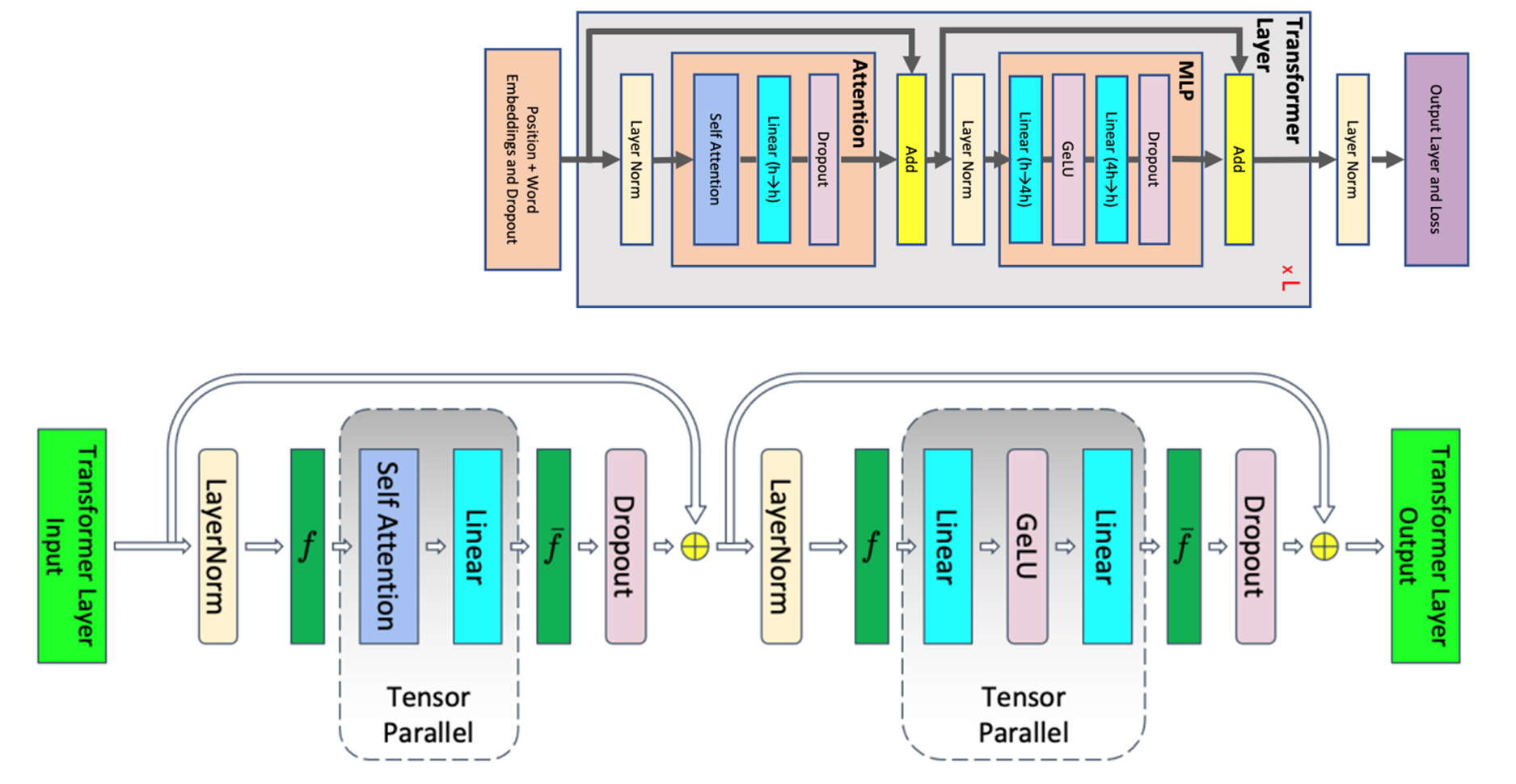
张量并行#
Megatron-LM#
[SPP+19]
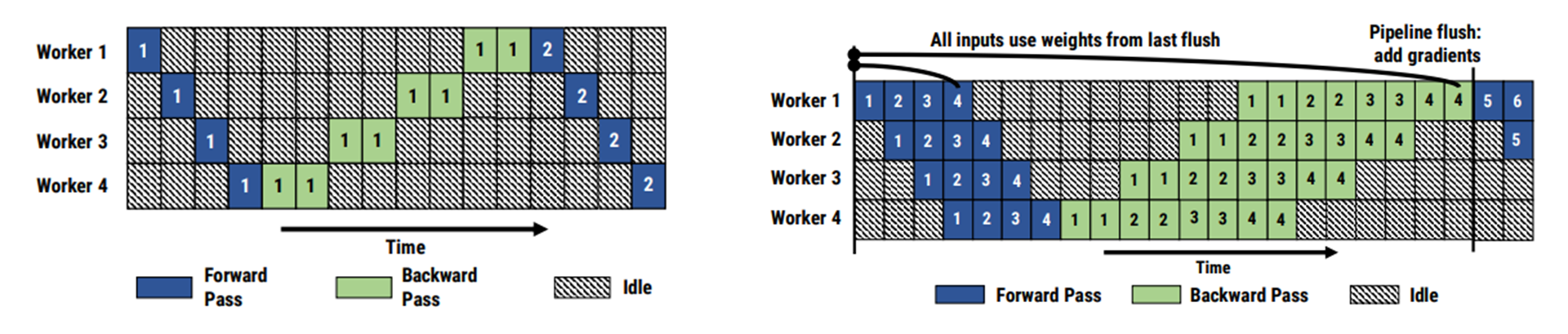
流水线并行#
PyTorch: Pipeline (GPipe)#
[HCB+19]
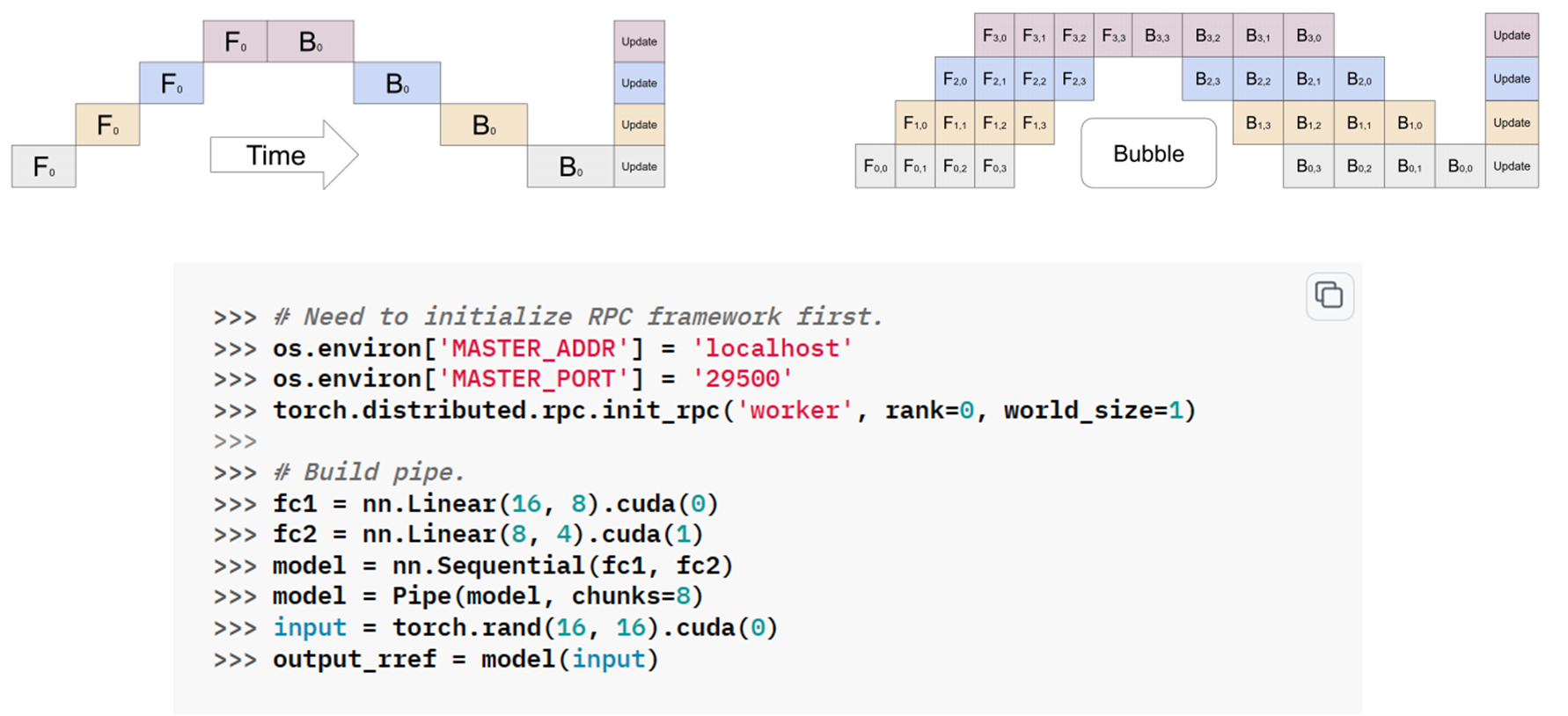
DeepSpeed: Pipeline (PipeDream)#
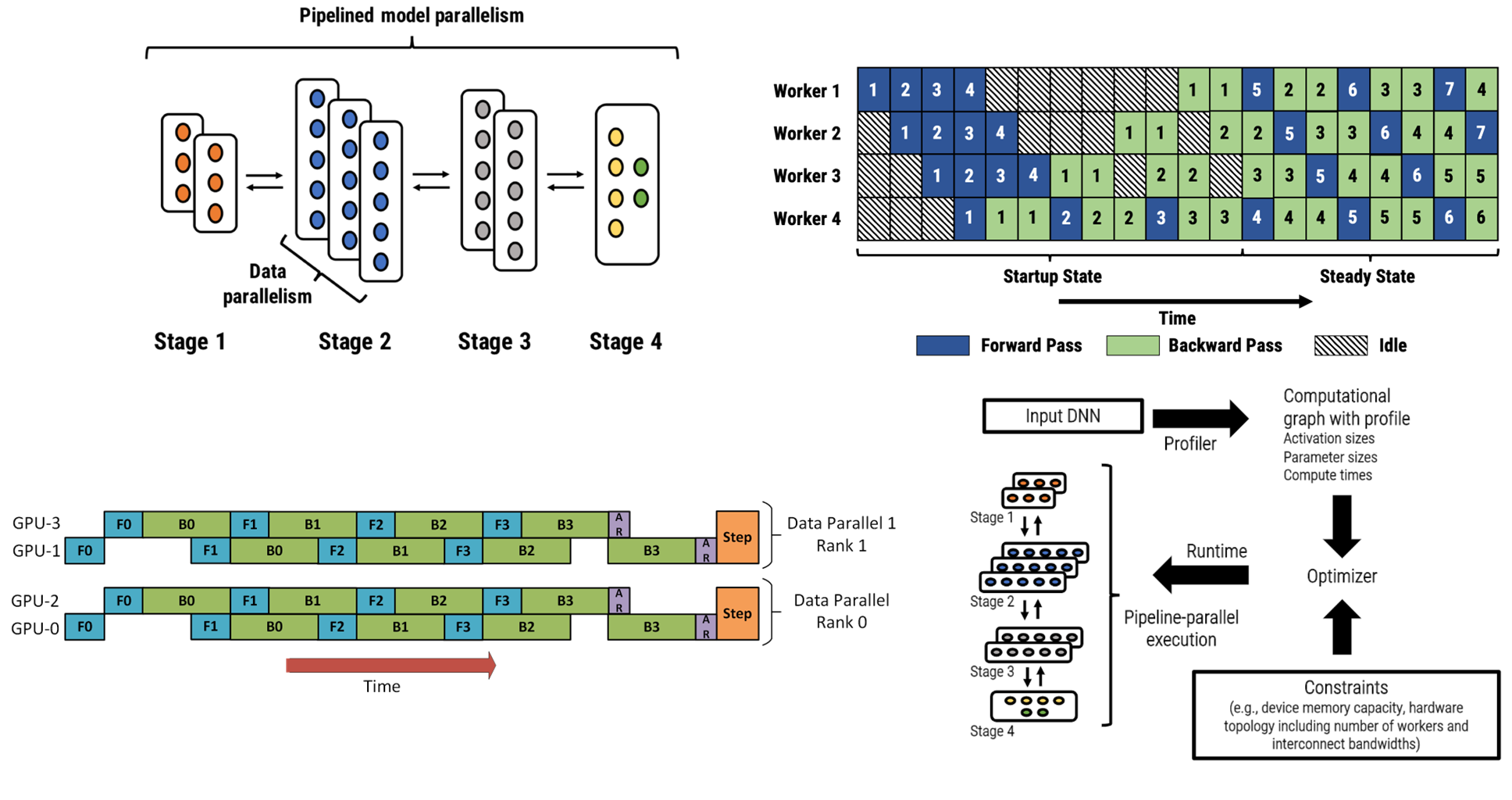
[NHP+19]
如何选择并行策略#
Efficient Training on Multiple GPUs (huggingface.co)

显存优化技巧#
Offload
Checkpointing [CXZG16]
优化器 LARS, LAMB, Adafactor
梯度累加
混合精度
- CXZG16
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- HCB+19
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and others. Gpipe: efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 2019.
- NHP+19
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, 1–15. 2019.
- RRRH20
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, 1–16. IEEE, 2020.
- RRR+21
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. Zero-infinity: breaking the gpu memory wall for extreme scale deep learning. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 1–14. 2021.
- RRA+21
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. Zero-offload: democratizing billion-scale model training. In USENIX Annual Technical Conference, 551–564. 2021.
- SPP+19
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.