Deep learning for seeing through window with Raindrops
Quan, Yuhui, Shijie Deng, Yixin Chen, and Hui Ji. "Deep Learning for Seeing Through Window With Raindrops." In Proceedings of the IEEE International Conference on Computer Vision, pp. 2463-2471. 2019. [PDF]
这篇文章考虑 Derain 问题中的一个子问题,就是透过有雨滴的窗户拍照得到的图片的恢复。就是处理如下的这种图片。文章的亮点主要在于使用了结合shape-prior和channel的Attention机制,以及非常好的数值结果。

这篇文章的Motivation是通过shape-driven attention和channel re-calibration来帮助CNN更好的恢复原图。
shape-driven attention
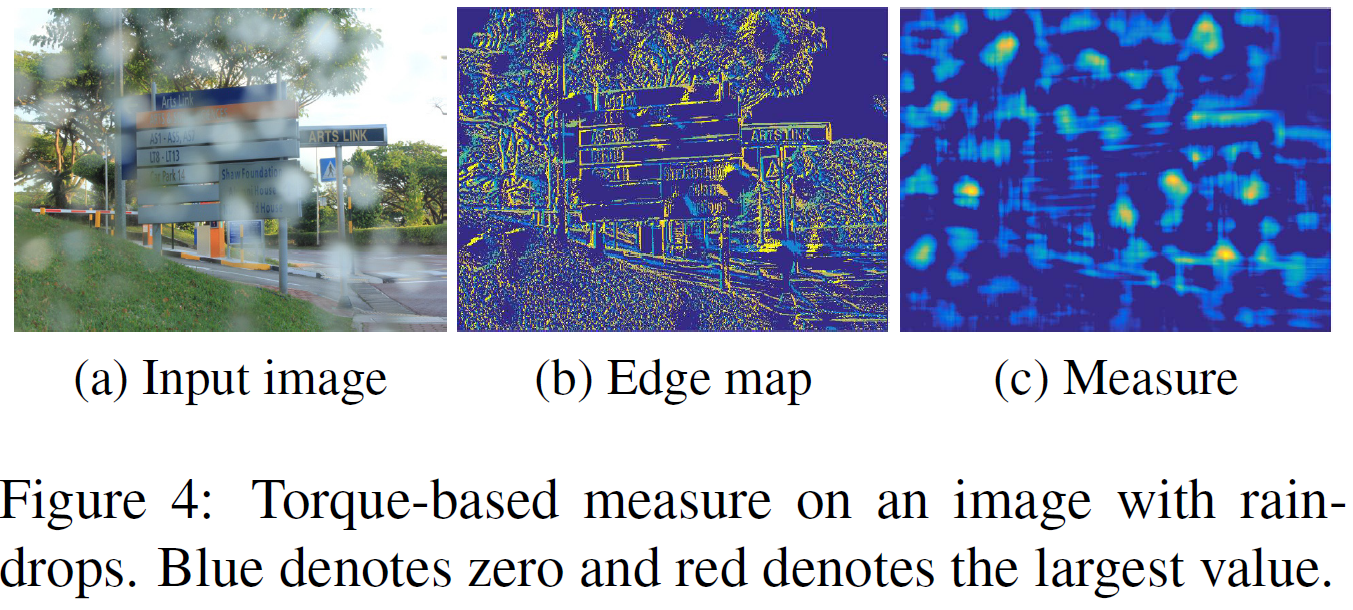
假设雨滴是椭圆形的。我们可以用图像某部分的edge map,即图像的patch的edge map和椭圆的等高线做内积,内积越大,则这个patch越接近一个椭圆(给定的长短轴参数a,b)。具体方法如下
\(f(x,y)=\frac{x^2}{a^2}+\frac{y^2}{b^2}\)是椭圆的等高线,则\(g(x,y)=[-\frac{\partial f}{\partial y},\frac{\partial f}{\partial x}]=[\frac{y}{b^2},\frac{x}{a^2}]\)是椭圆的edge方向。而图像用函数\(P(x)\)表示,图像的edge方向是\(e(x,y)=[-\frac{\partial P}{\partial y},\frac{\partial P}{\partial x}]\)
则\(\beta(x_0,y_0)=e(x_0,y_0)\cdot g(x_0,y_0)\)就表示图像在\((x_0,y_0)\)点的边缘和一个中心在\((0,0)\),长短焦为 \(a,b\) 的椭圆走势一致。 \[ \tau(P)=\sum_{(x_0,y_0)\in D(P)} \beta(x_0,y_0)/\# D(P) \] 就表示这个 patch 块中的图像是否接近一个以这个Patch中心为中心(且长短焦为$a,b $)的椭圆。
如果我们已经知道了图像的edge,那么\(\tau(P)\)的计算是可以用卷积来实现的。 \[ \tau(P_n)=\tau_1(P_n)+\tau_2(P_n) \]
\[ \tau_1(P)=\sum_{(x_i,y_i)\in D(P)} \frac{x_i}{a^2} \frac{\partial P_n}{\partial x}/\# D(P) \]
\[ \tau_2(P)=\sum_{(x_i,y_i)\in D(P)} \frac{y_i}{b^2} \frac{\partial P_n}{\partial y}/\# D(P) \]
Network Architecture
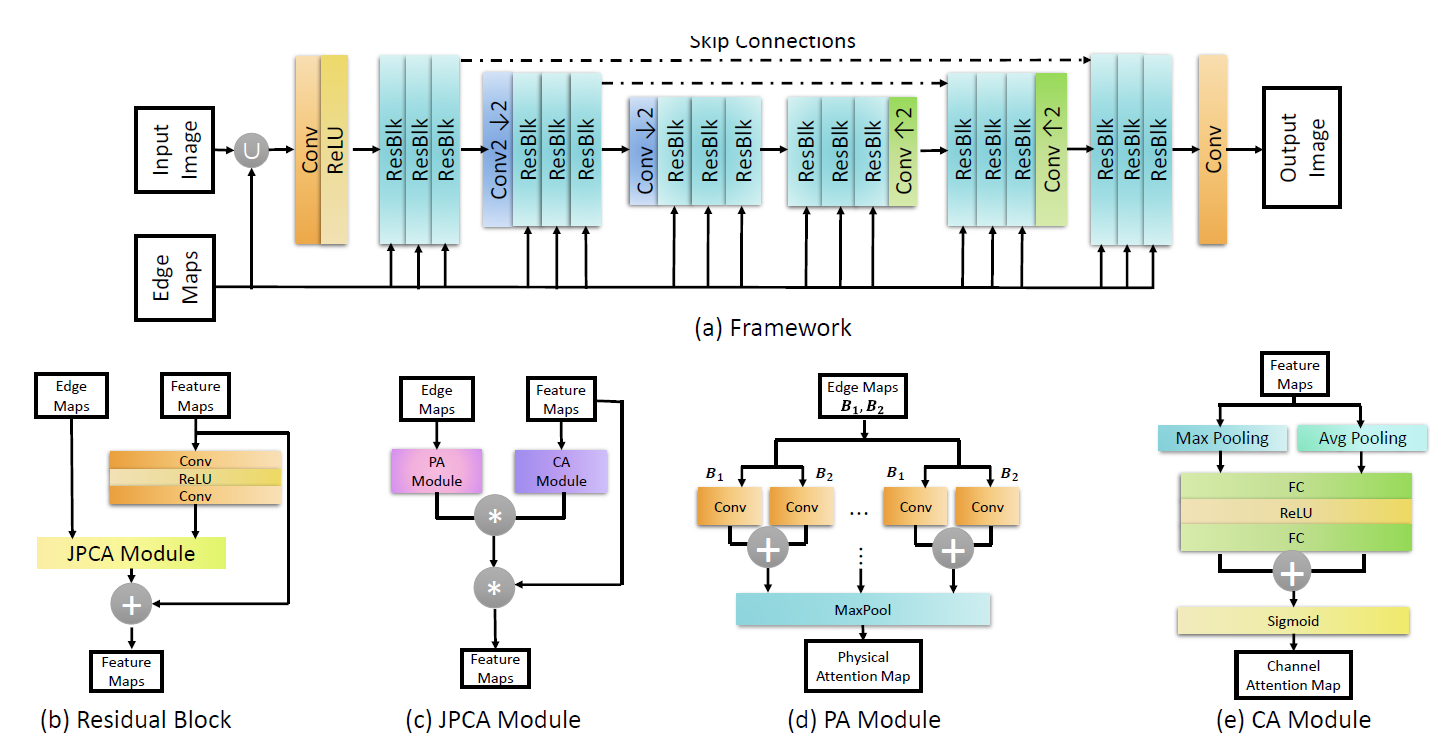
网络结构总体上是一个encode-decoder模型,图片和edge-maps先concat在一起,然后经过卷积以及一系列ResBlock和下采样上采样过程,以及为了加速训练的skip-connection。结构和其他的网络差别点主要在于其Residual Block。
Residual Block中结构大概为\(F'=F+F \cdot(PA(E)\cdot CA(F))\)。
其中PA是根据Edge-map计算shape-driven attention的过程,也就是前一节所说,图像和一些卷积核相乘来得到shape-attention,这些卷积核每个卷积核只有两个参数\(a,b\)。实际是取不同的Patch大小,分别是\(15 \times 15\),\(20\times 20\),..., \(40 \times 40\),并在每个尺度,给8组椭圆参数(即8组卷积核),这些参数是可学习的。
CA(F)则是用来得到channel attention,结构是Pooling+FC。
PA输出一个\(1 \times H \times W\)的tensor,CA输出一个\(C\times 1\times 1\)的tensor,两者做张量积得到\(C\times H\times W\)的Attention并用于Residual Block中。
网络的Loss则是L1-loss \[ L=\frac{1}{N}\sum_{i=1}^N||\hat X_i=X_i||_1 \]
Result
数值实验是在Qian et al.1发布的数据集上进行的。对比试验是Eigen et al2的方法,Qian et al.的AttentGAN3,以及Pix2Pix4 进行了对比试验。

Ablation study
作者做了分别拿走PA,CA模块和全拿走的对比实验。(如果拿走某个模块, 就把这个模块的输出恒定为0.5)。对比试验显示,JPCA模块对结果有较大提升,其中CA模块的贡献比PA模块更大。
Learning From Synthetic Photorealistic Raindrop for Single Image Raindrop Removal
Hao, Zhixiang, Shaodi You, Yu Li, Kunming Li, and Feng Lu. "Learning From Synthetic Photorealistic Raindrop for Single Image Raindrop Removal." In Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 0-0. 2019.
这篇文章恰好和上一篇一样,都是处理derain中的同一类问题,透过有雨滴的窗户拍照。这篇文章主要贡献在于 提出了第一个合成粘附雨滴训练的照片现实数据集。渲染是基于物理的,考虑了水的形状和光学性质。在此基础上, 提出了能很好地恢复图像结构的去除网络。
Refaction Model


这是本文的物理模型,其中绿线代表直接射进镜头的光线,而黄线表示经过两次折射后射入镜头的光线。
Raindrop Imagery Model and Photorealistic Dataset
作者根据上一节的物理模型,使用几何渲染和光线追踪技术,先随机生成玻璃角度、水滴的几何形状(水滴和玻璃的夹角以及水滴的直径)和位置,然后计算出我们在玻璃后应该观察出的图像,最后,考虑到摄像机的焦面在图像上,而玻璃上的水滴不在焦平面上,所以对水滴再进行了一个disk blur。 就得到了模拟数据集,效果如下,第一到三行分别为真实图像,模拟的玻璃后图像,和模拟图像的水滴mask。


Network Structure
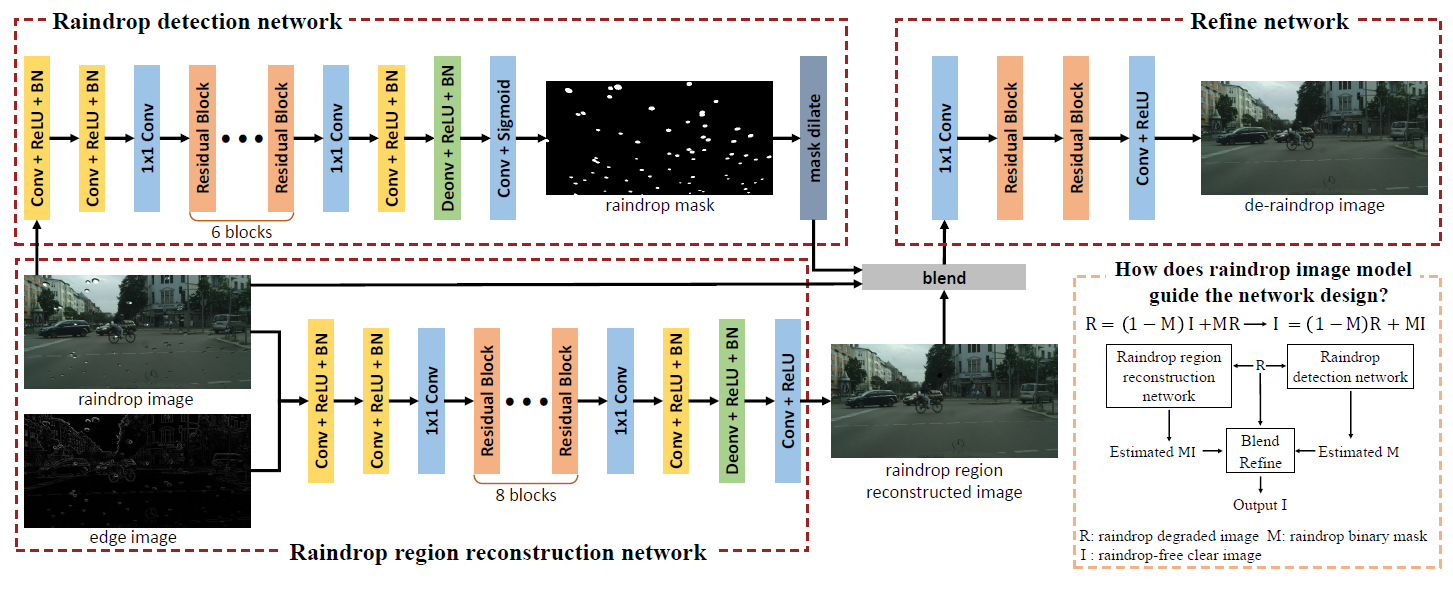
网络结构是一个two-stage的网络,分别有一个网络探测水滴位置,输出水滴mask。这个网络的训练需要雨滴mask的groundtruth。还有一个网络直接输入图像和edge image,输出重建图像,这个网络的训练需要真实图像。最后一个网络的输入是前两个网络的输出,输出真实图像,也是以真实图像作为Label进行训练。
作者发现如果对raindrop 探测网络的输出进行dilate再输入到第三个网络中效果会更好,否则可能会产生artifact.
Result


模拟数据集上网络表现很好,其中3RN only表示只用Raindrop region reconstruction network。
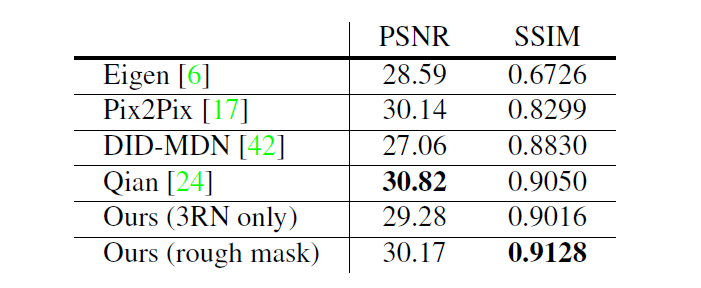
在真实数据集(和上边一篇文章一样,Qian的数据集)上,该算法的优势没有那么明显,因为该数据集没有雨滴的mask数据集,只能使用3RN only的网络,或者用雨滴图-原图得到rough mask进行训练。
Rui Qian, Robby T. Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In Proc. IEEE Conf. Comput. Vision Pattern Recognition, pages 2482–2491, 2018.↩︎
David Eigen, Dilip Krishnan, and Rob Fergus. Restoring an image taken through a window covered with dirt or rain. In Proc. Int. Conf. Comput. Vision, pages 633–640, 2013↩︎
Rui Qian, Robby T. Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In Proc. IEEE Conf. Comput. Vision Pattern Recognition, pages 2482–2491, 2018.↩︎
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A.Efros. Image-to-image ranslation with conditional adversarial networks. In Proc. IEEE Conf. Comput. Vision Pattern Recognition, pages 5967–5976. IEEE, 2017↩︎